2025. 3. 16. 18:41ㆍData Engineering/BigQuery
들어가며
지난 글에서는 Dremel 논문[1]을 통해서 Nested Data(중첩 데이터)를 저장하기 위한 아이디어인 반복 레벨과 정의 레벨에 대해 살펴보았습니다. 오늘은 논문의 뒷부분인 반복 레벨과 정의 레벨을 이용해 효율적으로 column stripe를 생성하는 방법과 이를 다시 레코드로 바꾸는 방법을 알아보도록 하겠습니다. 그리고 이렇게 만들어진 레코드를 어떻게 쿼리로 처리하는지까지 살펴보도록 하겠습니다.
*column stripe: 컬럼 기반 저장 방식에서 데이터를 나누는 단위.
✅ 레코드 -> 컬럼
Google에서 사용하는 많은 데이터는 희소한(Sparse) 형태, 예를 들자면 수천 개의 필드 중 실제로 값이 존재하는 필드는 백개 정도에 불과하는 형태를 갖고 있었습니다. 때문에 사용되는 필드를 효율적으로 처리하는 것이 중요했습니다. Dremel은 이를 위해 Field Writer 라는 트리 구조를 사용했습니다. 이 트리는 스키마의 필드 계층 구조, 즉 중첩된 구조를 그대로 반영합니다.
- Field Writer는 필드가 데이터를 가지고 있을 때에만 업데이트 됩니다.
- 부모 필드의 상태를 자식 필드로 불필요하게 전파하지 않습니다.
- 대신 자식 필드는 부모의 반복 레벨과 정의 레벨을 상속받으며, 데이터가 추가될 때마다 레벨을 동기화합니다.
✅ 컬럼 -> 레코드
이번에는 컬럼 형태로 바꾼 데이터를 다시 레코드로 합치는 과정을 살펴보겠습니다. 이 과정에서는 Finite State Machine(FSM)이 사용됩니다. FSM은 데이터를 순서대로 처리하고 레벨에 따라 레코드를 구성합니다. 동작 방식은 다음과 같습니다.
- FSM은 시작부터 끝까지 한 번씩 이동하며 데이터를 처리합니다.
- 각 단계에서는 현재 필드 f의 필드 리더가 반환하는 반복 레벨 l을 확인합니다.
- 반복 레벨 l에서 가장 가까운 조상 필드를 찾고, 해당 조상 필드 내에서 첫번째 리프 필드 n을 선택합니다.
FSM transition (f, l) -> n

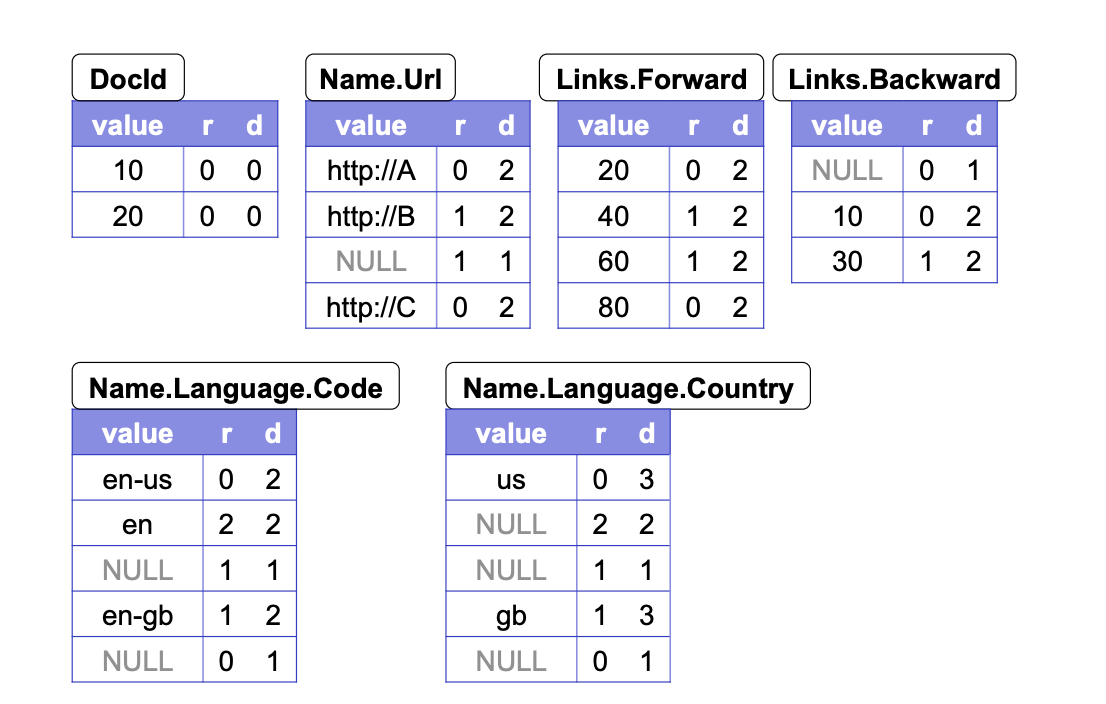
지난 글의 데이터를 예시로 조금 더 쉽게 이해해보겠습니다.
- 현재 필드 f = Name.Language.Contry이고 반복 레벨 l = 1이라고 하겠습니다.
- 이때 반복 레벨 1을 가지는 가장 가까운 조상은 Name 필드입니다.
- Name 필드 내부에서 현재 필드 Language.Contry 다음의 첫 번째 리프 필드는 Name.Url이 됩니다.
FSM transition(Name.Language.Contry, 1) -> Name.Url

✅ 쿼리 실행 (Query Execution)
Dremel은 Multi-Level Serving Tree를 사용해서 입력받은 쿼리를 실행합니다. 각 서버의 역할은 다음과 같습니다.
- 루트 서버: 쿼리를 입력받아 테이블의 메타데이터를 기반으로 어떻게 데이터를 처리할지 결정하고 다음 단계로 전달.
- 중간 서버: 데이터를 집계하는 역할을 하며 리프 서버에서 받은 결과를 처리.
- 리프 서버: 스토리지 레이어와 통신하거나 로컬 디스크의 데이터읽어 반환.

SELECT 문을 사용한 예시를 보겠습니다.
SELECT A, COUNT(B) FROM T GROUP BY A
만약 위와 같은 쿼리가 입력되면 루트 서버는 테이블 T를 구성하는 모든 파티션(수평 파티션)을 확인하고 재작성합니다.
SELECT A, SUM(c) FROM (R1_1 UNION ALL ... R1_n) GROUP BY A
여기서 R1_n은 서빙 트리의 각 노드에서 실행되는 하위 쿼리의 결과를 의미합니다. 실제로 실행되는 쿼리는 다음과 같습니다.
R1_i = SELECT A, COUNT(B) AS c FROM T1_i GROUP BY A
각 쿼리는 리프 서버로 전달되며 테이블 T를 병렬로 스캔합니다. 이후 중간 서버에서 결과를 집계합니다.
마치며
이번 글에서는 지난 글에서 못다 한 내용, 중첩된 데이터가 컬럼 형태로 저장되고 다시 레코드로 변환되는 과정과 SQL 쿼리가 실행되는 방식에 대해서 살펴보았습니다. 빅쿼리를 사용하면서도 기반이 되는 Dremel에 대해 고민해본적은 없었는데 이번 기회로 논문을 읽고 동작 방식을 이해해볼 수 있었습니다. 빅쿼리를 사용하시는 분들께도 도움이 되었기를 바라며, 다음 글로 돌아오도록 하겠습니다☘️
참고 자료
[1] Dremel 관련 논문
Dremel: Interactive Analysis of Web-Scale Datasets
Distributed Systems and Parallel Computing
research.google
'Data Engineering > BigQuery' 카테고리의 다른 글
| BigQuery에서 Nested Data의 처리: Dremel 논문으로 이해하기①🕵️♀️ (0) | 2025.03.02 |
|---|---|
| Kafka와 BigQuery를 활용한 데이터 파이프라인을 개선해보자☘️ (feat. MERGE문) (0) | 2025.01.19 |
| 데이터 분석의 경계에 선 엔지니어의 <인프런 BigQuery(SQL) 활용편>후기 (feat. 빠짝 스터디)🌱 (2) | 2024.11.24 |
| 이직 5개월 차의 BigQuery 최적화: 파티셔닝과 클러스터링으로 시작하기 (1) | 2024.10.27 |