2024. 10. 27. 23:51ㆍData Engineering/BigQuery
들어가며
최근에 읽고 있는 『구글 빅쿼리 완벽 가이드』 7장 성능 및 비용 최적화에는 컴퓨터 과학자 도널드 커누스의 말이 나옵니다.
"효율성은 향상시키려는 노력의 약 97%는 그 효과가 미비하므로 너무 집착해서는 안 된다. 성급한 최적화는 모든 문제의 근원만 될 뿐이다. 하지만 정말 중요한 3%의 최적화까지 포기해서는 안 된다."
빅쿼리를 사용한지도 어언 5개월입니다. 입사 초반에는 빅쿼리 UI에 뜨는 작은 바이트 수 변화 하나에도 집착하던 시기가 있었는데요, 아마 97%의 비효율적인 노력이 아니었나 싶습니다. 돌이켜보면 가장 빠르게 적용할 수 있고, 즉각적인 효과를 볼 수 있었던 3%의 가장 중요한 최적화는 파티셔닝과 클러스터링이었던 것 같아요. 오늘은 저와 같은 빅쿼리 초보자를 위한 파티셔닝과 클러스터링 최적화에 대해 알아보겠습니다.
1. 파티셔닝
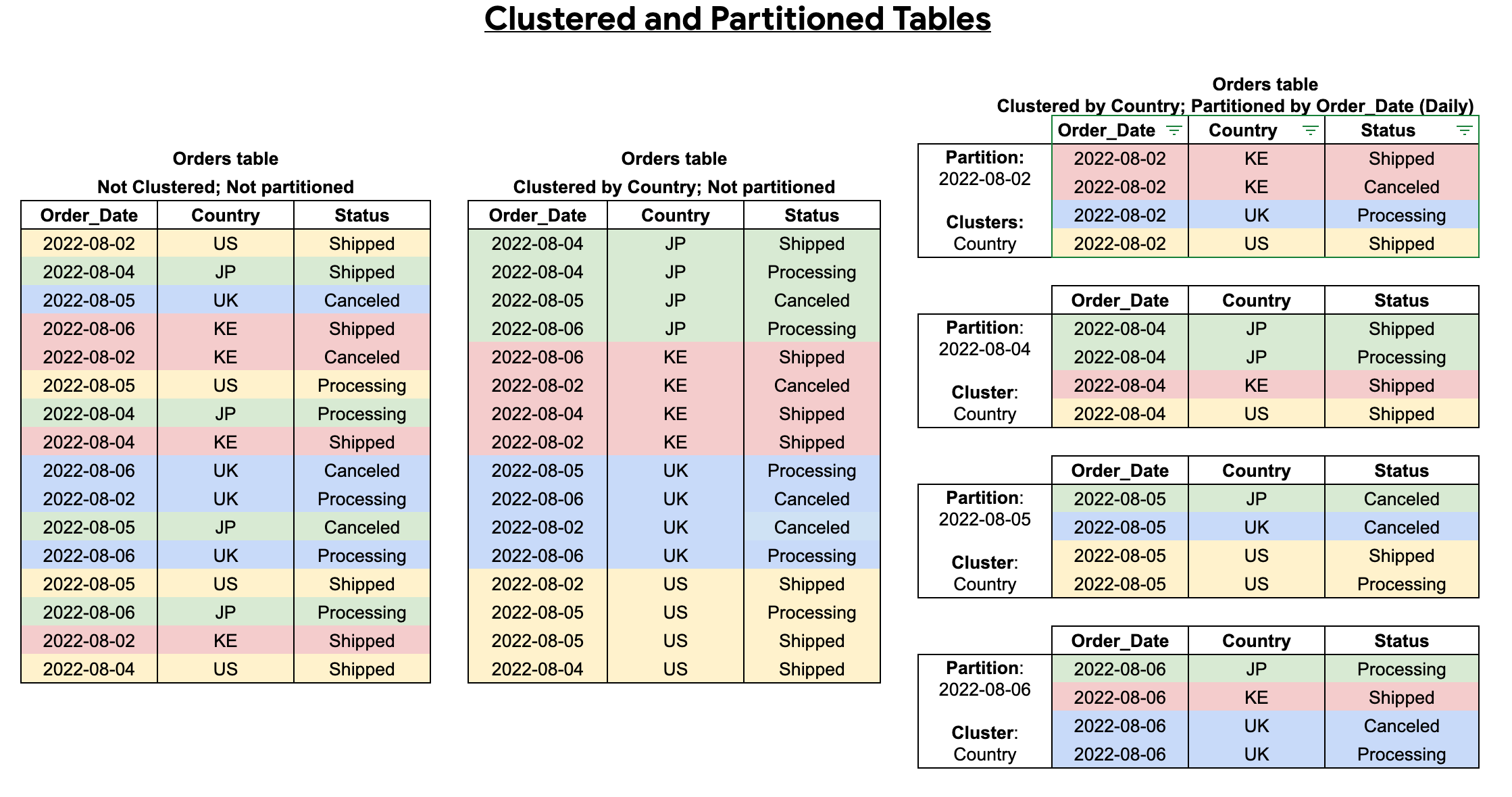
파티셔닝이란 테이블을 파티션이라는 세그먼트로 나누는 것을 말합니다. 테이블을 생성할 때 파티션 컬럼을 지정할 수 있으며 테이블 당 하나의 열만 설정할 수 있습니다. 빅쿼리에서는 항상 얼마나 많은 데이터를 읽는 지를 주의해야 하는데요, 파티션 컬럼으로 필터링을 하면 일치하는 데이터만 스캔해 성능을 높이고 비용을 낮출 수 있습니다. 이를 프루닝이라고 합니다.
1-1. 파티셔닝 테이블 생성
파티셔닝된 테이블을 만드는데는 여러 방법이 있지만 그중 SQL의 DDL문을 사용하는 방법은 아래와 같습니다.
CREATE TABLE
[DATASET].[TABLE] (transaction_id INT64, transaction_date DATE)
PARTITION BY
transaction_date
1-2. 파티셔닝 주의사항
파티션 프루닝을 하기 위해서는 필터에서 상수 표현식을 사용해야 합니다. 다시 말해 `WHERE` 절에서 파티션 컬럼과 비교하는 값이 다른 필드의 값에 따라 동적으로 바뀐다면 프루닝 하지 않습니다.
실제로 매일 스냅샷을 쌓는 테이블의 당일 데이터만 보기 위해 뷰를 사용하고 있었는데, 쿼리의 비용이 이상하게 높게나와 확인해 보니 파티션 프루닝이 되고 있지 않았던 적이 있습니다.


쿼리 확인 후 바로 팀 내부에 공유하였고 D-1일의 데이터인 `DATE_ADD(CURRENT_DATE, INTERVAL -1 DAY)` 형태로 모든 뷰를 변경할 수 있었습니다.
✔️ 파티션 사용 필수 옵션
-- 파티션 사용 필수 옵션 적용
ALTER TABLE [DATASET].[TABLE]
SET OPTIONS (
require_partition_filter = true);
쿼리 수정과 더불어 현재는 스냅샷 테이블에 대해 `require_partition_filter` 옵션도 `true`로 주었습니다. 파티션을 꼭 사용할 수 있도록 변경하였기에 이제 쿼리를 실행하면 `Cannot query over table '[DATASET].[TABLE]' without a filter` 에러가 발생하게 됩니다.

1-3. 테이블 당 최대 파티션 수
2024년인 현재 사용할 수 있는 테이블 당 최대 파티션 수는 10,000개입니다(관련 문서). 단, 단일 작업(각 쿼리 또는 로드 작업)으로 수정할 수 있는 파티션의 수는 4,000개로 제한된다고 합니다.
2. 클러스터링
다음으로 클러스터링이란 사용자가 정의한 열에 따라 데이터를 정렬하는 것을 말합니다. 클러스터링 열은 스토리지 블록 수준에서 정렬되며, 블록 크기는 테이블 크기에 따라 조정됩니다. 클러스터링 열을 기준으로 필터링이나 집계를 하면 관련된 블록만 스캔할 수 있습니다.

클러스터링 열은 2개 이상 지정할 수 있는데 효과를 보기 위해서는 1) 쿼리에서 사용하는 필터의 순서가 클러스터링된 열 순서와 일치해야 하며 2) 최소한 클러스터링된 첫 번째 열이 포함되어야 합니다.
2-1. 클러스터링 테이블 생성
파티셔닝 테이블과 마찬가지로 SQL의 DDL 문을 사용해 클러스터링 된 테이블을 만들 수 있습니다.
CREATE TABLE [DATASET].[TABLE]
(
timestamp TIMESTAMP,
id STRING,
transaction_amount NUMERIC
)
PARTITION BY DATE(timestamp)
CLUSTER BY
id
만약 이미 만들어진 테이블에 클러스터링 컬럼을 추가하고 싶다면 bq명령줄 도구를 사용할 수 있습니다.
# 클러스터링 사양 업데이트
bq update --clustering_fields=[CLUSTER_COLUMN] [DATASET].[TABLE]
# 새 사양에 따라 모든 행 업데이트
UPDATE [DATASET].[TABLE] SET [CLUSTER_COLUMN]=[CLUSTER_COLUMN] WHERE true
2-2. 파티셔닝과 클러스터링
파티셔닝과 클러스터링 둘 다 최적화를 위한 방법인 것은 알겠는데 어떤 것을 쓸지 고민될 수 있습니다.
이에 대한 기준은 구글 문서에 어느정도 가이드가 나와 있습니다. 우선 1) 파티션을 나누었을 때 파티션 당 10GB 미만인 경우 클러스터링 사용을 권장합니다. 이는 작은 파티션을 여러 개 만들게 되면 메타 데이터가 증가하여 쿼리 성능에 영향을 미치기 때문입니다.
또한 2) 컬럼의 카디널리티가 높아 파티션 수 제한을 넘기는 경우, 3) 테이블을 쿼리 할 때 필터 또는 집계를 자주 사용하는 경우에 클러스터링을 사용하는 것이 좋습니다. 이때, 테이블(또는 파티션)의 크기가 64MB보다 커야 클러스터링을 통한 최적화 효과를 볼 수 있습니다.
3. 사용해보기
업무에서는 주로 파티셔닝과 클러스터링을 같이 사용합니다. 파티셔닝은 주로 수집 일자에, 클러스터링은 주로 조인이나 집계, 필터링에 자주 사용되는 ID값에 적용합니다. 특정 컬럼에 대한 필터링이 자주 일어난다면 해당 컬럼에 적용하기도 합니다.
예를 들어 강의 클립 수강시간을 구하기 위해
1. 일별 고객의 수강시간이 스냅샷 형태로 쌓이는 테이블의 수집 일자(`DATE`)에 파티셔닝을 하고
2. 값이 실제로 쌓인 시간(`TIMESTAMP`)에 클러스터링을 해 일별 수강시간 값을 구할 수 있습니다.
기존에는 파티셔닝은 대부분 사용하고 있었지만, 클러스터링은 많이 사용되고 있지 않아 최적화할 대상이 보이면 팀 내 공유하고 하나씩 수정해나가고 있습니다.

3-1. 업무 시 주의사항
✔️ 적용 전 운영 중인 파이프 라인 확인
새롭게 테이블을 만드는 경우라면 상관없지만, 기존의 테이블에 클러스터링 컬럼을 추가(또는 변경)하는 것이라면 운영 중인 파이프라인에 에러가 발생할 수 있는지를 꼭 확인해야 합니다.
실제로 이를 제대로 확인하지 않고 클러스터링을 추가했다가 다음날 에어플로우 배치 파이프라인에서 에러를 발생시킨 경험이 있습니다. 기존 파이썬 코드 중 `QueryJobConfig`에 `clustering_fields`가 없었던 것이 원인이었습니다.
job_config = bigquery.QueryJobConfig(
destination="{destination}${selectedDateBigQuery}".format(
destination=destination, selectedDateBigQuery=selectedDateBigQuery
),
write_disposition="WRITE_TRUNCATE",
time_partitioning=bigquery.table.TimePartitioning(field=partition_field),
# 클러스터링 필드 추가
clustering_fields=clustering_fields,
)
✔️ 모든 테이블 업데이트 여부 확인
데이터를 매일 스냅샷 형식으로 저장하는 테이블이라면 그동안 쌓인 모든 데이터에 클러스터링을 적용할 필요가 없을 수 있습니다. 이런 경우 클러스터링 컬럼만 업데이트해 이후의 데이터에만 적용할 수 있습니다.
빅쿼리 파티션, 클러스터링의 개념과 일에서의 경험을 정리해 보았습니다. 앞으로도 빅쿼리 성능을 높이기 위한 방법들을 계속해서 찾아가고 공유하도록 하겠습니다!
내용 중 잘못된 부분이나 더 나은 방법이 있다면 언제든 댓글로 말씀해 주세요🙇♂️
참고 자료
테이블 소개 | BigQuery | Google Cloud
BigQuery의 테이블, 해당 유형(BigQuery 테이블, 외부 테이블, 뷰), 제한사항, 할당량, 가격 책정을 설명합니다.
cloud.google.com
구글 빅쿼리 완벽 가이드 - 예스24
빅데이터, 데이터 엔지니어링, 머신러닝을 위한 대용량 데이터 분석과 처리의 모든 것협업과 신속함을 갖춘 작업 공간을 구축하는 동시에 페타바이트 규모의 데이터셋을 처리해보자. 이 책은
m.yes24.com
'Data Engineering > BigQuery' 카테고리의 다른 글
| BigQuery에서 Nested Data의 처리: Dremel 논문으로 이해하기②🕵️♀️ (0) | 2025.03.16 |
|---|---|
| BigQuery에서 Nested Data의 처리: Dremel 논문으로 이해하기①🕵️♀️ (0) | 2025.03.02 |
| Kafka와 BigQuery를 활용한 데이터 파이프라인을 개선해보자☘️ (feat. MERGE문) (0) | 2025.01.19 |
| 데이터 분석의 경계에 선 엔지니어의 <인프런 BigQuery(SQL) 활용편>후기 (feat. 빠짝 스터디)🌱 (2) | 2024.11.24 |