2024. 3. 9. 14:12ㆍData Engineering
지난 2월 퇴근 후 조금씩 시간을 내 작은 프로젝트를 진행했다. 회사에서는 이미 만들어진 빅데이터 플랫폼 위에서 운영업무를 하다 보니 파이프 라인을 비슷하게나마 직접 만들어보고 싶다는 마음에서부터였다. 데이터는 한번 사용해봐서 익숙한 도서 데이터를 선택했고, 주제는 책방 사장님의 큐레이션을 위한 도서 데이터 대시보드 구축으로 정했다.
이번 글에서는 프로젝트의 과정을 되돌아보고 회고를 남겨볼까 한다.
🙋♂️ 프로젝트 과정
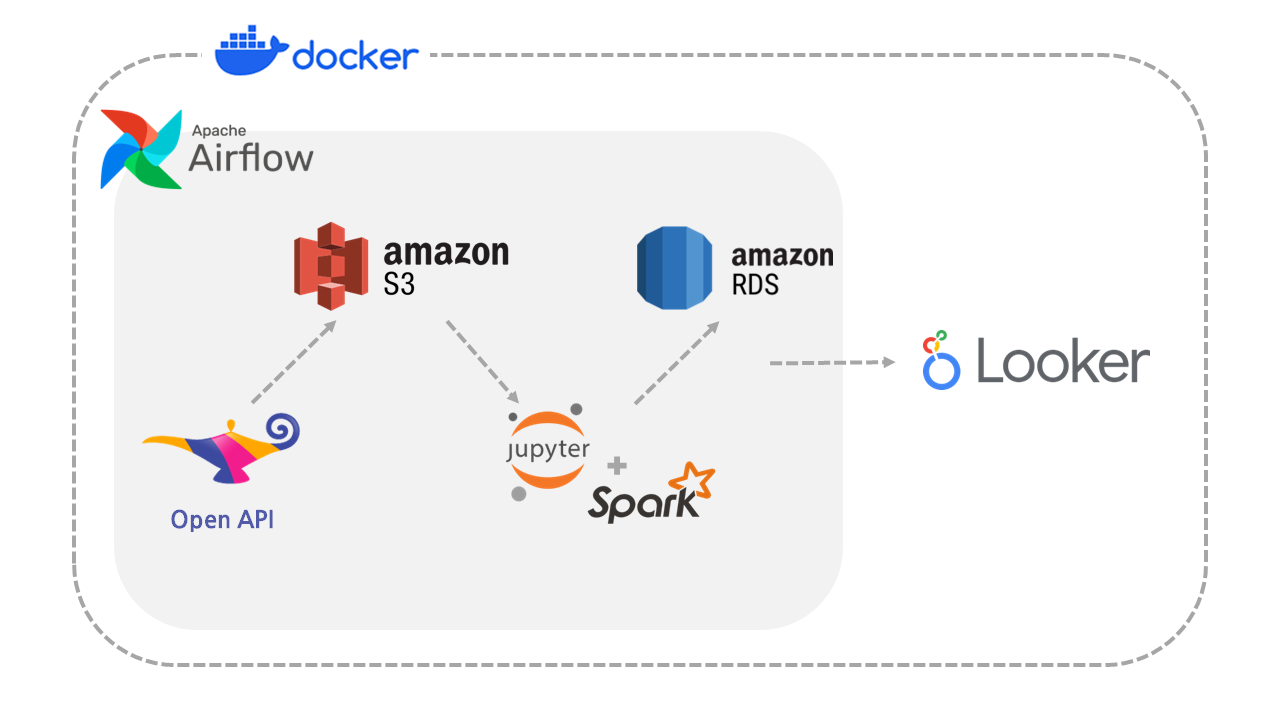
프로젝트는 Docker 환경에서 진행하였고 프로세스를 자동화할 수 있도록 Apache Airflow를 사용했다. 데이터는 온라인 서점 알라딘의 Open API를 활용했다. 개발 환경 및 프로세스는 다음과 같다.
개발 환경
- docker 4.7.0
- spark 3.3.4
- airflow 2.8.1
- python 3.8
- mysql 8.0.35
1. 데이터 Amazon S3에 적재
데이터는 온라인 서점 사이트 알라딘의 Open API를 활용했다(👉메뉴얼 바로가기). 데이터는 ISBN, 제목, 지은이, 카테고리, 가격, 출간일, 상품설명, 표지 URL, 상품 URL 그리고 알라딘 판매 지수인 세일즈 포인트 등으로 구성된다.

이후에는 Airflow에서 매달 실행될 DAG를 만들고 아래와 같이 태스크를 만들었다.
✔ Task 1: fetch_books_info
각 카테고리별로 도서 데이터를 데이터 프레임에 저장한 후 파일로 생성하는 태스크. 최종 파일은 books_YYYYMM.parquet 형식으로 저장된다.
def fetch_books_info(**context):
params = {
'ttbkey':'{TTBKEY}',
'QueryType':'Bestseller',
'MaxResults':'50',
'SearchTarget':'Book',
'output':'JS',
'Version':'20131101',
'Cover':'Big'}
cat_list = {
'소설/시/희곡':'1',
'경제경영': '170',
'과학':'987',
'사회과학':'798',
'에세이':'55889',
'역사':'74',
'예술/대중문화':'517',
'인문학':'656',
'자기계발':'336',
'장르소설':'112011',
'가정/요리/뷰티':'1230',
'건강/취미/레저':'55890',
'좋은부모':'2030',
'컴퓨터/모바일':'351',
'여행':'1196',
'청소년':'1137',
'고전':'2105'}
df = pd.DataFrame() # 도서 정보를 저장할 데이터 프레임 생성
for cat_name in cat_list.values():
for page in range(1, 15): # 총 결과는 1,000개까지만 조회 가능(페이지 당 50권)
API_URL = f'http://www.aladin.co.kr/ttb/api/ItemList.aspx?&Start={page}&CategoryId={cat_name}'
raw_data = requests.get(API_URL, params=params)
try:
parsed_data = json.loads(raw_data.text, strict=False)
df = pd.concat([df, pd.DataFrame(parsed_data['item'])])
except json.JSONDecodeError as e:
print(f"Error decoding JSON: {e}")
continue
# 부가 정보 필드 제거
df = df.drop('subInfo', axis=1)
etl_date=datetime.now().strftime("%Y%m")
context['ti'].xcom_push(key="etl_date", value=etl_date)
# Parquet 파일로 저장
df.to_parquet(f"/opt/airflow/data/raw/books_{etl_date}.parquet")
✔ Task 2: upload_to_s3
생성한 parquet 파일을 Amazon S3 버킷에 저장하는 태스크. airflow의 xcom을 사용해 날짜 변수를 가져오고 이 날짜에 해당하는 parquet 파일을 업로드한다.
def upload_to_s3 (bucket_name: str, **context) -> None:
hook = S3Hook('aws_conn')
etl_date = context['ti'].xcom_pull(key="etl_date")
filename=f"/opt/airflow/data/raw/books_{etl_date}.parquet"
key=f"raw/books_{etl_date}.parquet"
print(f"filename: {filename}")
print(f"key: {key}")
hook.load_file(
filename=filename,
key=key,
bucket_name=bucket_name,
replace=True
)
2. Spark를 사용한 데이터 전처리
전처리 작업을 위해 Airflow와는 별도의 Ubuntu 컨테이너를 만들었다. 여기에 Apache Spark를 설치하고(Single Node) 사용자가 pyspark로 데이터 분석을 할 수 있도록 Jupyter Notebook에 연결했다.
간단한 전처리 과정은 다음과 같다.
# preprocessing_data.ipynb
from pyspark.sql import SparkSession
from pyspark import SparkConf, SparkContext
from pyspark.sql.functions import *
from pyspark.sql.types import StringType
from datetime import datetime
conf = SparkConf()
spark = SparkSession.builder \
.config(conf=conf) \
.appName("spark_test") \
.getOrCreate()
# conf 값 확인
spark.sparkContext.getConf().getAll()
# S3의 데이터 가져오기
etl_date=datetime.now().strftime("%Y%m")
df = spark.read.format('parquet').load(f's3a://aladin-books-bucket/raw/books_{etl_date}.parquet')
# 사용하지 않는 컬럼 제거
cols = ('isbn', 'itemId', 'priceSales', 'mallType', 'stockStatus', 'mileage', 'categoryId', 'adult', 'fixedPrice', 'seriesInfo')
df = df.drop(*cols)
# ISBN 번호 기준 중복 도서 제거
df = df.dropDuplicates(['isbn13'])
# 제목 내 설명 제거
df = df.withColumn('title', regexp_replace('title', '\s-\s.*|\s:\s.*|(\+).+', ''))
# 제목 내 특수문자 제거
df = df.withColumn('title', regexp_replace('title', '[\{\}\[\]\/?.,;:|\)*~`!^\-_+<>@\#$%&\\\=\(\'\"]', ''))
# 지은이 추출
df = df.withColumn('writer', trim(regexp_replace('author', '(\().*', '')))
# 출간일 분리
df = df. \
withColumn('pubYear', date_format('pubDate', 'yyyy')). \
withColumn('pubMonth', date_format('pubDate', 'MM')). \
withColumn('pubDay', date_format('pubDate', 'dd'))
# 카테고리 분리
df = df. \
withColumn('1stClass', split('categoryName', '>').getItem(1)). \
withColumn('2ndClass', split('categoryName', '>').getItem(2)). \
withColumn('3ndClass', split('categoryName', '>').getItem(3))
# 사용하지 않는 컬럼 제거
cols = ('author', 'pubDate', 'categoryName', '__index_level_0__')
df = df.drop(*cols)
# 최종 스키마 확인
#df.printSchema()

3. 최종 데이터 Amazon RDS에 적재
전처리를 마친 후에는 Amazon RDS에 데이터를 저장했다.
df.write \
.format("jdbc") \
.option("driver","com.mysql.cj.jdbc.Driver") \
.option("url", "jdbc:mysql://{ENDPOINT}:{PORT}/dm_aladin") \
.option("dbtable", "aladin_bestseller_books_mm") \
.option("user", "{USER}") \
.option("password", "{PASSWORD}") \
.option("truncate", "true") \
.mode("overwrite") \
.save()
이 주피터 노트북 파일( .ipynb )은 파이썬 파일(.py)로 변경해 Airflow DAG에서 실행할 수 있게 하였다.
*nbconvert를 사용하면 주피터 노트북 파일을 다른 파일 형식으로 변환할 수 있다.
✔ Task 3: run_spark_job
SSH Operator를 사용해 전처리 파일을 실행하는 태스크.
run_spark_job = SSHOperator(
task_id='run_spark_job',
ssh_hook = SSHHook(
ssh_conn_id='spark_conn',
remote_host='172.18.0.8',
username='{USER}',
password='{PASSWORD}'
),
command = 'python aladin_pipline/preprocessing_data.py > aladin_pipline/preprocessing_data.log 2>&1',
dag=dag
)
✔️ 전체 DAG 확인하기
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.providers.amazon.aws.hooks.s3 import S3Hook
from airflow.providers.ssh.operators.ssh import SSHOperator
from airflow.providers.ssh.hooks.ssh import SSHHook
from datetime import datetime
import requests
import json
import pandas as pd
def fetch_books_info(**context):
params = {
'ttbkey':'{TTBKEY}',
'QueryType':'Bestseller',
'MaxResults':'50',
'SearchTarget':'Book',
'output':'JS',
'Version':'20131101',
'Cover':'Big'}
cat_list = {
'소설/시/희곡':'1',
'경제경영': '170',
'과학':'987',
'사회과학':'798',
'에세이':'55889',
'역사':'74',
'예술/대중문화':'517',
'인문학':'656',
'자기계발':'336',
'장르소설':'112011',
'가정/요리/뷰티':'1230',
'건강/취미/레저':'55890',
'좋은부모':'2030',
'컴퓨터/모바일':'351',
'여행':'1196',
'청소년':'1137',
'고전':'2105'}
df = pd.DataFrame() # 도서 정보를 저장할 데이터 프레임 생성
for cat_name in cat_list.values():
for page in range(1, 15): # 총 결과는 1,000개까지만 조회 가능(페이지 당 50권)
API_URL = f'http://www.aladin.co.kr/ttb/api/ItemList.aspx?&Start={page}&CategoryId={cat_name}'
raw_data = requests.get(API_URL, params=params)
try:
parsed_data = json.loads(raw_data.text, strict=False)
df = pd.concat([df, pd.DataFrame(parsed_data['item'])])
except json.JSONDecodeError as e:
print(f"Error decoding JSON: {e}")
continue
# 부가 정보 필드 제거
df = df.drop('subInfo', axis=1)
etl_date=datetime.now().strftime("%Y%m")
context['ti'].xcom_push(key="etl_date", value=etl_date)
# Parquet 파일로 저장
df.to_parquet(f"/opt/airflow/data/raw/books_{etl_date}.parquet")
def upload_to_s3 (bucket_name: str, **context) -> None:
hook = S3Hook('aws_conn')
etl_date = context['ti'].xcom_pull(key="etl_date")
filename=f"/opt/airflow/data/raw/books_{etl_date}.parquet"
key=f"raw/books_{etl_date}.parquet"
print(f"filename: {filename}")
print(f"key: {key}")
hook.load_file(
filename=filename,
key=key,
bucket_name=bucket_name,
replace=True
)
dag = DAG(
'aladin_bestseller_monthly_pipline',
start_date=datetime(2024, 3, 1),
catchup=False,
schedule_interval='@monthly'
)
fetch_books_info = PythonOperator(
task_id='fetch_books_info',
python_callable=fetch_books_info,
dag=dag,
provide_context=True
)
upload_to_s3 = PythonOperator(
task_id='upload_to_s3',
python_callable=upload_to_s3,
op_kwargs={
'bucket_name': 'aladin-books-bucket'
},
dag=dag,
provide_context=True
)
run_spark_job = SSHOperator(
task_id='run_spark_job',
ssh_hook = SSHHook(
ssh_conn_id='spark_conn',
remote_host='172.18.0.8',
username='{USER}',
password='{PASSWORD}'
),
command = 'python aladin_pipline/preprocessing_data.py > aladin_pipline/preprocessing_data.log 2>&1',
dag=dag
)
fetch_books_info >> upload_to_s3 >> run_spark_job
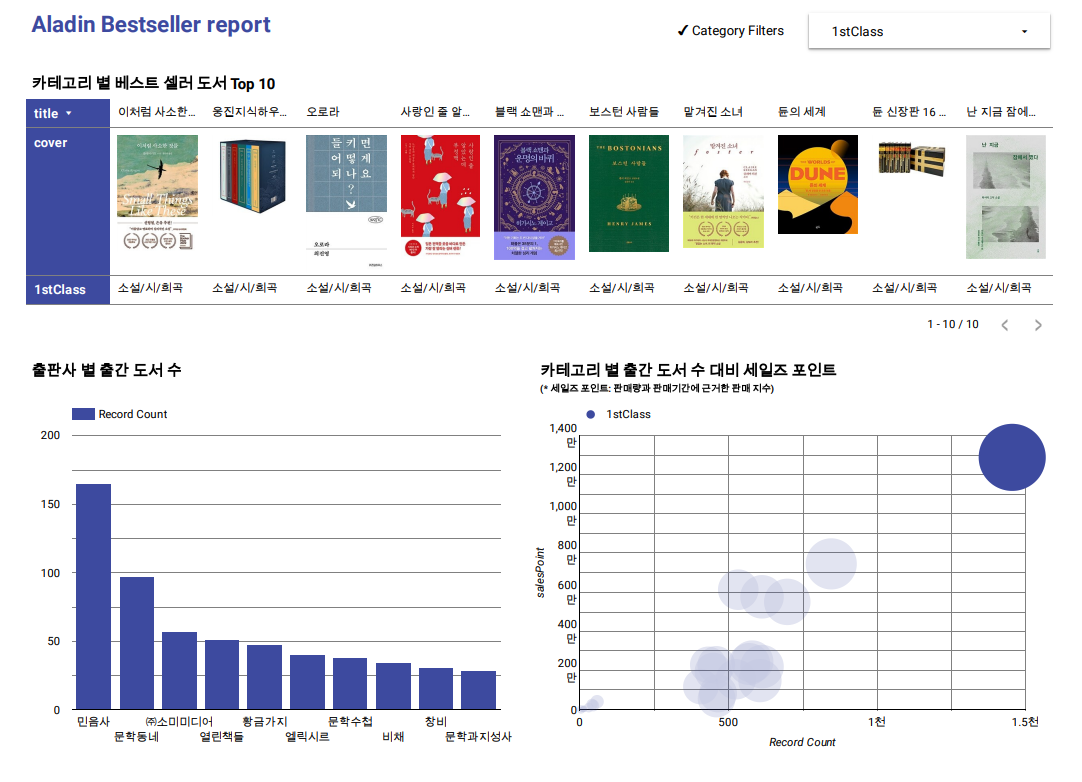
4. Google Looker Studio 대시보드 구축
최종적으로 Amazon RDS의 테이블과 Google Looker Studio(구 Data Studio)를 연결해 간단한 대시보드를 만들었다.
오른쪽 상단의 카테고리 필터를 사용하거나 그래프를 클릭하면 해당되는 데이터를 볼 수 있다. (@대시보드 바로가기)
✍️ 프로젝트 회고
프로젝트를 시작할 때 고려한 점
1) 데이터 저장소 분리: 수집 데이터와 가공 데이터를 서로 다른 저장소에 적재했다.
- 수집 데이터: 대용량의 데이터를 효율적으로 처리하기 위해 Amazon S3에 parquet 형식으로 적재
- 가공 데이터: 데이터를 구조화하고 관리하기 쉽도록 Amazon RDS에 적재
2) 편리한 사용 환경: Jupyter Notebook에서 Pyspark를 쓸 수 있는 환경을 만들어 사용자가 데이터 분석 및 전처리를 쉽게 할 수 있도록 했다.
프로젝트를 진행하며 아쉬웠던 점
AWS S3를 처음 사용해 보았는데 도커 컨테이너와의 연동 시 잘못된 버전의 JAR 파일을 다운로드해 애를 먹었던 기억이 있다. 시간을 많이 쓴 것이 아쉽지만, 덕분에 Maven repository에서 라이브러리 의존성을 꼼꼼히 확인하는 습관을 만들 수 있었다.
간단할 줄 알았는데 직접 만들어보니 역시나 쉽지 않았다. 그래도 완성해낸 기분은 뿌듯.
이번에는 혼자 진행했지만 다음번엔 데이터 분석가나 사이언티스트 분들과 함께 여러 문제들을 해결해보고 싶다.
'Data Engineering' 카테고리의 다른 글
| GCP 방화벽 설정: 인그레스 규칙으로 포트 연결 오류 해결하기 🔐 (0) | 2025.03.30 |
|---|---|
| PostgreSQL 핫 백업을 해보자 (feat. 젠킨스) (0) | 2024.11.10 |