2022. 3. 1. 01:17ㆍCode States AI
드디어 프로젝트가 끝이 났다(이주 전 프로젝트를 앞둔 심정은 여기서 확인).
끝이 난 기념으로 오늘은 간단한 프로젝트 소개글과 회고를 적어보려 한다. 우선 결과물을 보자.

제목에서 언급한 것처럼 프로젝트 주제는 알라딘 베스트셀러 데이터를 사용한 콘텐츠 기반 책 추천 웹 애플리케이션 제작이었다.
🙋♂️진행 과정
1) 데이터 선정 및 전처리


데이터는 온라인 서점 사이트 알라딘의 Open API를 활용했다(메뉴얼 바로가기). 제공하는 것 중에서 상품 리스트 API를 사용했고, 국내 베스트셀러 도서 데이터 약 1만 건을 제이슨 형식으로 추출했다. 속성은 도서의 고유한 식별자라 할 수 있는 국제 표준 도서번호 ISBN, 제목, 지은이, 세부 카테고리, 가격, 출간일, 상품설명, 책 표지 URL, 상품 URL 그리고 알라딘에서 측정하는 판매 지수인 세일즈 포인트를 사용했다.
전처리는 구글 colab환경에서 파이썬을 사용해 진행했다. 중복 데이터를 제거하고 정규표현식을 사용해 위 예시처럼 문자열 데이터를 처리해주었다. 날짜나 세부 카테고리처럼 테이블 내에서 분리해줄 수 있는 데이터도 분리해주었다. 도서 간의 유사도를 계산하기 위해 상품 설명에서 명사 키워드도 추출했다(한국어 형태소 분석기 KOMORAN사용)
2) 데이터 시각화


메인 주제는 웹 어플리케이션 제작이지만 기왕 데이터를 가져온 거 어떻게 생겼는지 궁금해서 시각화를 해봤다. 시각화에는 파이썬 라이브러리인 Matplotlib과 Seaborn을 사용했고, 데이터를 시대별로 나눈 후 카테고리 중심으로 차트를 그렸다. 왼쪽은 데이터 내에서 카테고리 별 출시량 대비 sales point를 버블 차트로, 오른쪽은 소설/시/희곡(대분류)에서 시대별로 사랑받은 중분류를 파이 차트로 나타낸 예시이다.
오른쪽 그래프를 보면 네 가지를 알 수 있다.
- 추리/미스터리 소설은 시대를 막론하고 꾸준히 인기 있었다.
- 2010년대에는 한국 소설이 상위 카테고리에 들어왔다. 젊은 작가들이 주목을 받았고 사회적 문제를 다루는 소설이 인기를 끌었다.
- 2020년대에는 과학소설(SF)이 상위 카테고리에 들어왔다. 과학 기술에 대한 관심과 더불어 김초엽, 천선란, 황모과 등 젊은 여성 작가들의 약진이 두드러졌다.
- 2020년대의 또 다른 특이점은 라이트 노벨이다. 라이트노벨은 일본에서 시작된 장르로 만화/애니메이션 풍의 일러스트가 들어간 소설 장르이다. 차트에서 가장 많은 비율을 차지했다.
시각화에 대한 해석과 더 많은 그래프는 아래 깃허브에서 확인할 수 있다.
GitHub - Donghae0230/Book_recommendation: 알라딘 베스트 셀러 데이터를 활용한 책 추천 웹 어플리케이션
알라딘 베스트 셀러 데이터를 활용한 책 추천 웹 어플리케이션 개발. Contribute to Donghae0230/Book_recommendation development by creating an account on GitHub.
github.com
3) 데이터 저장


데이터베이스는 PostgreSQL을 선택했다. ElephantSQL을 사용해서 PostgreSQL DB 인스턴스를 생성하고, 앞서 전처리한 데이터를 csv파일로 변환한 뒤 DBeaver를 사용해 import 해주었다.
데이터베이스에는 전체 도서 데이터를 담을 book, 사용자 데이터를 담을 user 테이블을 만들었다. 왼쪽은 ElephantSQL에서 book 테이블을 확인한 모습이다.
4) 추천 모델 생성


추천 시스템을 구현하는 과정이다. 나는 사용자가 좋아하는 도서를 입력하면 그와 유사한 도서를 추천해주는 컨텐츠 기반 추천 시스템을 만들고자 했다. 우선 데이터 베이스에서 문자열로 된 데이터를 사용해 데이터를 생성하고, 파이썬 gensim 패키지의 Word2Vec을 사용해 벡터화 시켜주었다. Word2Vec은 특정 단어 주변의 단어들을 활용해 벡터화를 진행한다. 데이터의 벡터, 즉 임베딩 벡터를 구하면 서로의 유사도를 계산할 수 있는 것이다.
유사도 계산에는 코사인 유사도를 사용했다. 두 벡터를 사용해 코사인 유사도를 계산했을 때 1에 가까울수록 유사도가 높다고 할 수 있다. 계산 결과는 웹 상에서 사용할 수 있도록 pickle 모듈을 사용해 바이너리 파일로 저장했다.
🙋♂️웹 앱 개발 및 배포


웹 프레임워크는 플라스크를 사용했다. HTML과 CSS를 사용해 직접 디자인했고, 모바일에서 사용하는 경우를 고려해 사이즈를 맞췄다(시간상 반응형까지는 구현하지 못했다😢) 배포는 해로쿠를 사용해 진행했다.
처음 링크로 접속하면 왼쪽과 같이 사용자와 도서 정보를 입력할 수 있는 폼이 뜬다. 여기서 사용자는 이름, 나이, 성별, 좋아하는 도서 명을 입력하게 되는데, 입력한 정보는 바로 데이터베이스에 쌓이도록 연결해두었다. 데이터베이스에 공백이 입력되는 것을 방지하기 위해 자바스크립트를 사용해 간단히 유효성 검사도 구현했다(공백 입력 시 경고창).
오른쪽은 검색 결과를 나타낸 페이지다. 앞서 데이터의 유사도를 바탕으로 여섯 권의 도서를 추천하도록 만들었다. 도서 리스트에는 표지, 제목, 작가, 출판사, 그리고 알라딘 상품 링크가 포함되어 있다.
https://nodobooks.herokuapp.com/
맞춤법과 띄어쓰기를 주의해주세요!
nodobooks.herokuapp.com
🙋♂️프로젝트 회고
1) 좋았던 점
- Open API로 데이터를 추출하고 DB에 저장하는 것에 보다 익숙해졌다.
- 추천 시스템에서 카운트 기반 방법을 사용한 지난번과 달리 예측방법인 Word2Vec을 활용해 유사도 행렬의 크기를 줄였다
(지난번 용량 문제로 배포 실패). - ISBN 코드로 도서를 검색했던 지난번과 달리 SQL쿼리를 활용해 제목 키워드로 검색할 수 있도록 개선했다.
- 기획부터 개발, 배포까지 모든 과정을 직접 해본 경험은 처음이라 뿌듯했다.
2) 아쉬운점
- 이전에도 언급했지만 형태소 분석기를 사용해 추출한 명사가 책을 대표한다고 말하기에 애매한 데이터가 꽤 있다. 키워드 데이터가 따로 있었다면 좋았을 것 같다.
- 유저의 도서 선호도 데이터가 있었다면 추천 시스템에서 협업 기반 필터링도 진행해볼 수 있었을 것 같아 아쉽다.
- 웹 사이트에 가보면 알겠지만 허점 투성이다.
사실 아쉬운 점을 쓰라하면 프로젝트 소개 분량만큼 쓸 수 있을 것 같다. 그래도 지난 세션에서 못다한 프로젝트를 끝내 마무리지은 나 자신에게 박수를😇
💙깨알 홍보와 감동의 후기들💙
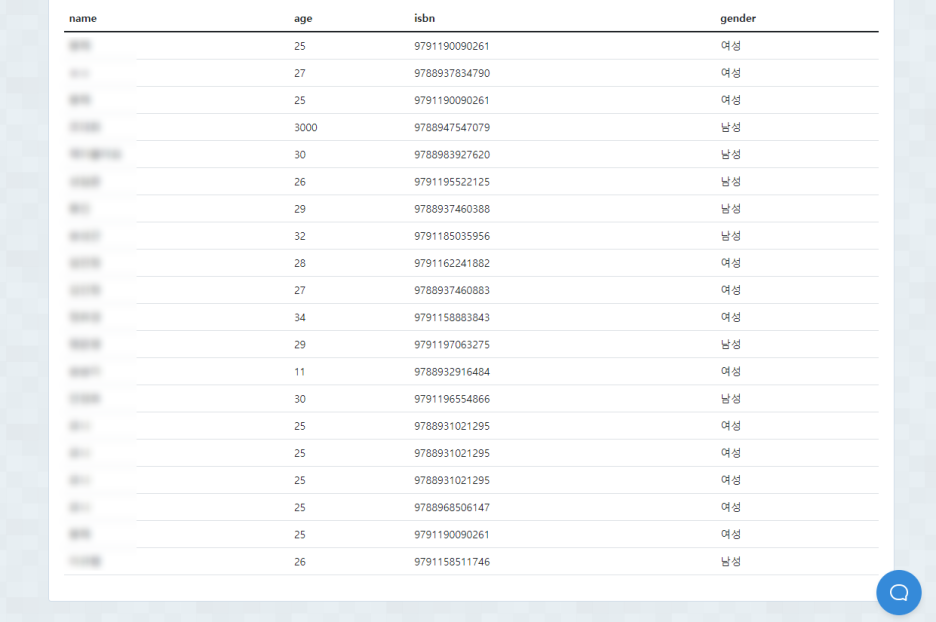
(나이 3000 검색하신 코치님,,,그 부분은 생각지도 못했는데 얼른 개선하겠습니다🤦♂️)
정말 후기 받으면서 눈물 줄줄😭😭 내가 만든 서비스를 누군가 사용한다고 생각하면 늘 설레었는데 이건 상상했던 것 이상이다. 얼른 더 큰 서비스에도 참여해보고 싶다. 그럼 프로젝트 소개 및 회고글은 여기서 진짜 끝끝

아직 열심히 공부중인 단계입니다. 부족한 부분에 대한 피드백은 언제나 환영입니다. 읽어주셔서 감사합니다.
'Code States AI' 카테고리의 다른 글
| [코드스테이츠/개인프로젝트] 2주 프로젝트를 앞둔 심정과 계획들😇 (2) | 2022.02.14 |
|---|---|
| [PYTHON/파이썬] KoBERT를 사용한 온라인 뉴스 악성 댓글 데이터 이진 분류 (2) | 2022.01.15 |
| [PYTHON/파이썬] 워드 클라우드(Word Cloud)로 한글 데이터 시각화하기 (0) | 2022.01.14 |